Optimizers are the most consequential part of deep learning that most practitioners never examine closely. You pick one, set a few hyperparameters, and move on.
That trust is mostly earned. AdamW has been the safe bet for years. But optimizers have a long, eventful history, and the landscape is shifting again. This post traces how we got here, what actually changed at each stage, and where it’s heading.
TL;DR
- AdamW is still the default for most deep learning training in early 2026, including LLMs, vision transformers, and diffusion models.
- SGD + momentum remains competitive for convolutional architectures with well-tuned schedules.
- Conditioning-based methods (Muon, NorMuon, TEON, ARO) are the most active research frontier, showing promising gains at 1B+ scale but not yet displacing AdamW in documented production recipes.
- Choosing the wrong optimizer, or misconfiguring the right one, can waste 10-30% of a training run’s compute budget. The payoff for getting this right scales with your training spend.
Mental model
The goal of training is to find model parameters that minimize error on the data. Backpropagation computes the gradient, a direction that tells each parameter how to change to reduce the loss. But that gradient comes from a mini-batch, not the full dataset, so it’s noisy. The optimizer decides what to actually do with it: how far to step, how to smooth out the noise, and what to remember from previous steps.
Those decisions break into four controls:
- Direction: where to move.
- Step size: how far.
- Stability: how to survive noise and curvature.
- Resource cost: memory, compute, and communication.
In notation: at step \(t\), the optimizer converts gradient \(g_t\) into update \(\Delta \theta_t\). Most of the history below is about doing that conversion better. Each wave solved one bottleneck, then exposed the next one.
Visual intuition
Here’s a quick look at what an optimizer actually does, through two examples. The task is classifying points from two interleaved spirals, a simple 2D dataset but one where the decision boundary is non-trivial.
The model is a small 2-layer neural network: 2 inputs, two hidden layers of 64 units with ReLU activations, and a 2-class softmax output (about 4,500 parameters total).
To visualize the training trajectory, we project the model’s parameters at each training step down to 2D using PCA. The surface shows the loss landscape in that projected plane.
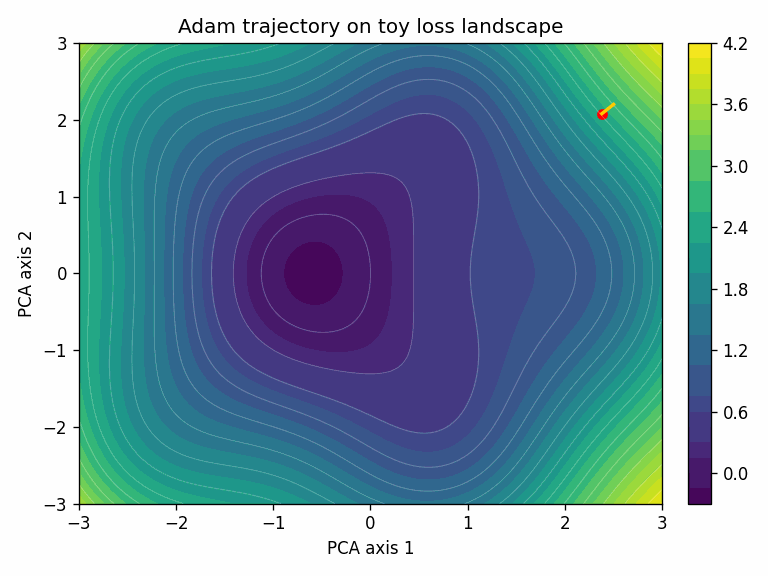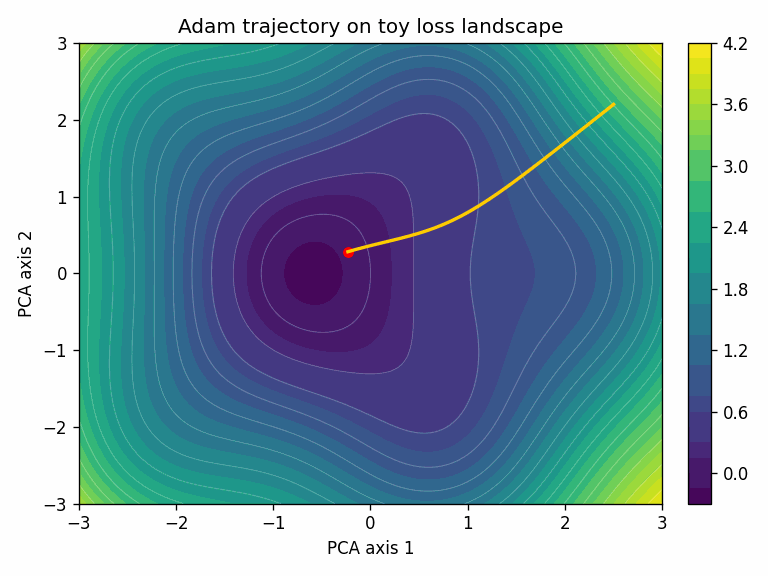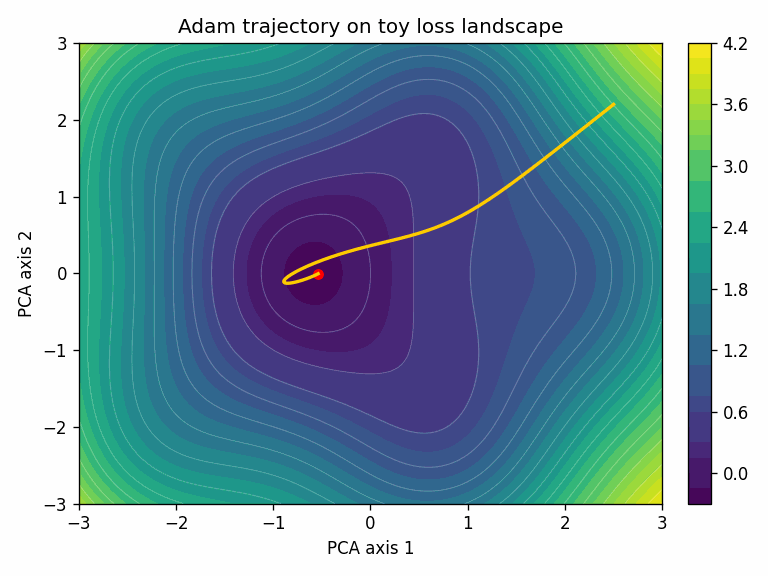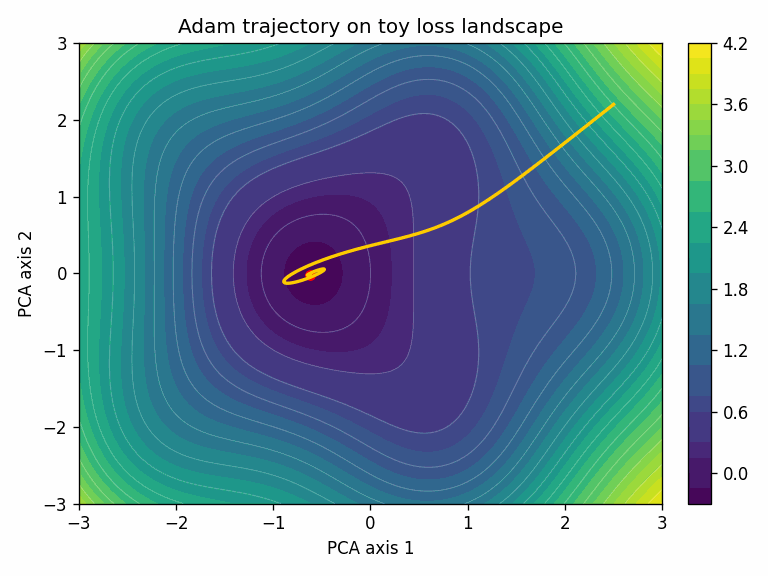
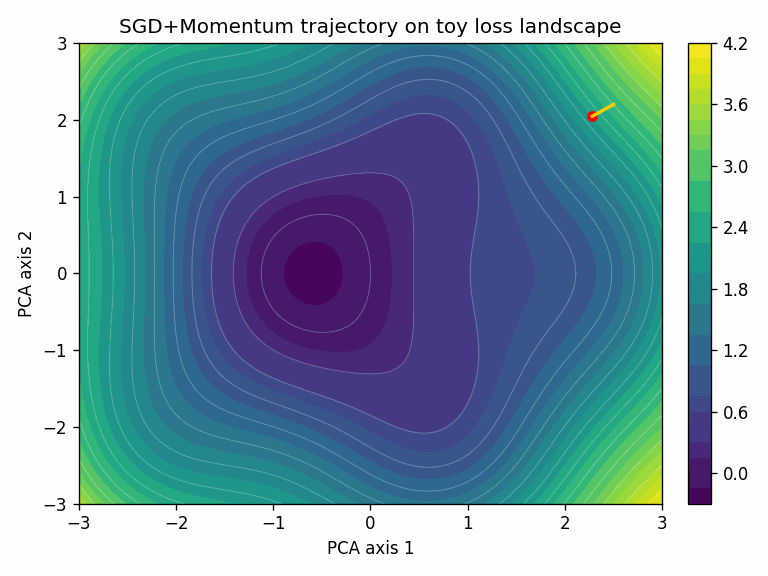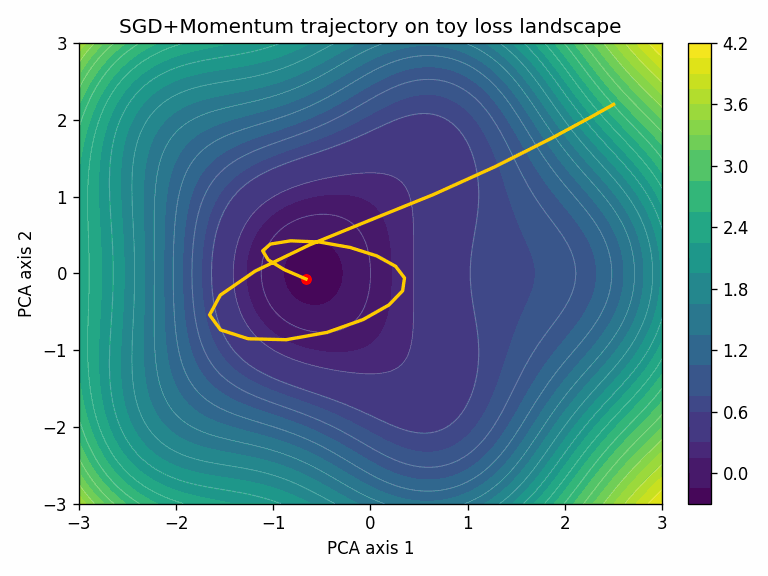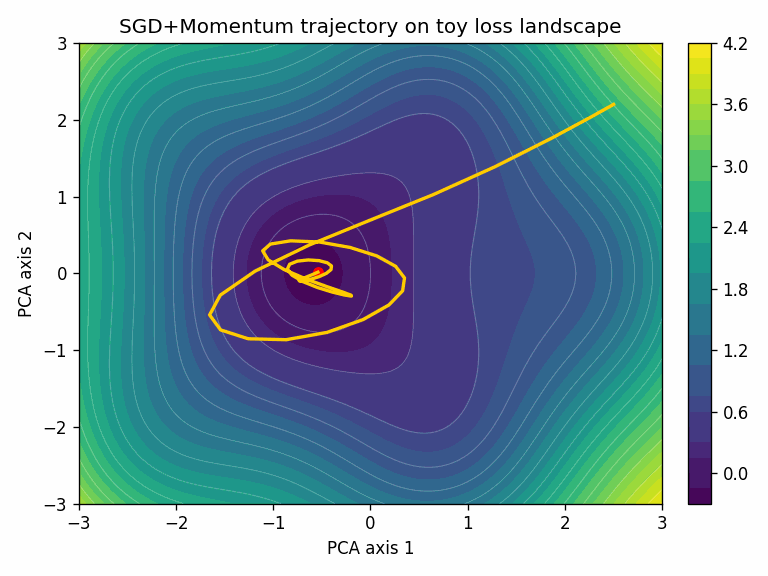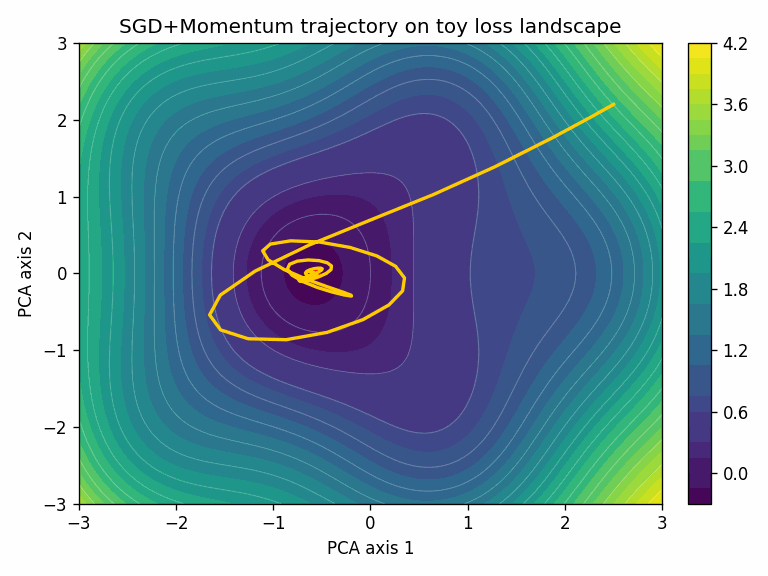
In this toy task, Adam converges faster. That’s not always the case; SGD + momentum with a well-tuned schedule often generalizes better, especially for convolutional architectures.
1960s to 2000s: foundations that never went away
In classical optimization, Newton’s method converges fast by using the full curvature of the loss surface (the Hessian). But the Hessian for a model with \(n\) parameters is an \(n \times n\) matrix; for a 7B-parameter model, that’s unthinkable. Plain gradient descent avoids this cost but converges slowly on ill-conditioned problems. The entire history of deep learning optimizers lives in the gap between those two extremes: get some of Newton’s speed without Newton’s cost.
The first key ideas predate modern deep learning:
- Polyak momentum (heavy ball) reduced zig-zag behavior in narrow valleys by accumulating a velocity term \(v\) (Polyak, 1964). Instead of stepping directly in the gradient direction, each update blends the current gradient with the previous velocity, so the optimizer builds up speed in consistent directions and dampens oscillations in noisy ones:
\[ v_{t+1} = \beta\, v_t + g_t,\qquad \theta_{t+1} = \theta_t - \eta\, v_{t+1}, \qquad v_0 = 0. \]
Here \(\eta\) is the learning rate (step size), and \(\beta \in [0, 1)\) controls how much history to keep. With \(\beta = 0\) this reduces to plain gradient descent.
- Nesterov acceleration (Nesterov, 1983) observed that standard momentum commits to a direction before seeing the gradient there. The fix: compute the gradient at a look-ahead position \(\theta_t - \eta\beta\, v_t\), where momentum is already taking you, then correct course:
\[ v_{t+1} = \beta\, v_t + \nabla f(\theta_t - \eta\beta\, v_t), \qquad \theta_{t+1} = \theta_t - \eta\, v_{t+1}. \]
Compare with Polyak momentum above: the only change is where the gradient is evaluated. Instead of \(\nabla f(\theta_t)\), we use \(\nabla f(\theta_t - \eta\beta\, v_t)\). This “peek ahead” reduces overshooting and improves convergence on smooth objectives. Nesterov momentum appears in many high-performing SGD recipes today. - Natural gradient (Amari, 1998) addressed a different problem: standard gradient descent depends on how you parameterize the model. Amari proposed using the Fisher information matrix to define steepest descent in the space of distributions rather than the space of parameters. This makes the update invariant to reparameterization. The cost is prohibitive for large models (the Fisher is as expensive as the Hessian), but the idea directly inspired the scalable approximations K-FAC and Shampoo that appear later.
All three pointed in the same direction: a better-informed step is worth extra compute, up to a point. Finding that point is the recurring tension of optimizer design, and the rest of this post is largely about where different eras drew the line.
2010 to 2014: getting deep nets to train at all
Early deep learning leaned on SGD + momentum because it was cheap and scalable, but tuning was fragile (Sutskever et al., 2013).
In practice, engineers could train deeper models, but only with careful learning-rate schedules and a lot of trial and error.
Adaptive methods arrived quickly, each one fixing a limitation of the last:
- AdaGrad (2011) addressed a specific problem: in sparse settings (e.g. NLP with large vocabularies), rare features receive too-small updates under a single global learning rate. AdaGrad scales each parameter by the inverse square root of its accumulated squared gradients (Duchi et al., 2011):
\[ h_t = h_{t-1} + g_t^2, \qquad \Delta\theta_t = -\frac{\eta}{\sqrt{h_t} + \epsilon}\, g_t. \]
Parameters with consistently large gradients get smaller steps; rare-but-informative parameters get larger ones. The weakness: \(h_t\) only grows, so effective step sizes shrink monotonically. For long training runs on deep nets, learning can stall.
- RMSProp (2012) fixed this by replacing the cumulative sum with an exponential moving average, so old gradients are forgotten (Hinton lecture notes, 2012):
\[ h_t = \rho\, h_{t-1} + (1-\rho)\, g_t^2, \qquad \Delta\theta_t = -\frac{\eta}{\sqrt{h_t} + \epsilon}\, g_t. \]
With \(\rho\) typically around 0.9, the denominator adapts to recent curvature rather than all of history. RMSProp became a practical default and the direct precursor to Adam.
- AdaDelta (2012) took a different approach: it eliminated the global learning rate entirely by normalizing updates using a running average of past updates, not just past gradients (Zeiler, 2012). Less common today, but it showed that the learning rate itself could be made adaptive.
By the end of this period, the design direction was clear: momentum-like smoothing plus per-parameter adaptive scaling. That combination set up Adam’s rapid adoption in the next wave.
2014 to 2019: Adam wins, AdamW corrects
Adam became the default because its out-of-the-box hyperparameters worked reasonably well across tasks, with much less tuning than SGD required (Kingma and Ba, 2014).
The idea: combine momentum (a running average of gradients, like Polyak) with per-parameter scaling (a running average of squared gradients, like RMSProp). Note: \(v_t\) here is the second moment estimate, unrelated to the velocity \(v\) in momentum above.
\[ m_t=\beta_1 m_{t-1}+(1-\beta_1)g_t,\qquad v_t=\beta_2 v_{t-1}+(1-\beta_2)g_t^2. \]
Notice the \((1-\beta)\) weighting on the current gradient. Polyak momentum accumulates gradients (\(v \leftarrow \beta v + g\)), so its magnitude scales as roughly \(1/(1-\beta)\): change \(\beta\) and you need to retune the learning rate. Adam uses exponential moving averages (EMAs) instead, so \(m_t\) stays on the same scale as individual gradients regardless of \(\beta_1\). This decouples the smoothing decision (how many past steps to blend) from the step-size decision (how far to move).
That normalization enables Adam’s core insight. After bias correction (\(\hat{m}_t = m_t / (1-\beta_1^t)\) and \(\hat{v}_t = v_t / (1-\beta_2^t)\), where the exponent \(t\) is the step number), the update is:
\[ \Delta\theta_t=-\eta\frac{\hat m_t}{\sqrt{\hat v_t}+\epsilon}. \]
The ratio \(\hat{m}_t / \sqrt{\hat{v}_t}\) has an intuitive interpretation as a signal-to-noise ratio. \(\hat{m}_t \approx \mathbb{E}[g]\) is the mean gradient: the consistent signal. \(\hat{v}_t \approx \mathbb{E}[g^2]\) captures both signal and noise. When the gradient for some parameter consistently points the same way, \(|\hat{m}_t|\) is large relative to \(\sqrt{\hat{v}_t}\), and Adam takes a confident step close to \(\pm\eta\). When the gradient is noisy and flips sign, \(|\hat{m}_t|\) shrinks (positive and negative values cancel in the average) while \(\hat{v}_t\) stays large (squared values don’t cancel). The ratio drops, and Adam steps cautiously. In fact, by Jensen’s inequality (\(\mathbb{E}[g]^2 \leq \mathbb{E}[g^2]\)), the ratio is bounded: each parameter’s step is at most \(\eta\).
Typical defaults (\(\beta_1=0.9\), \(\beta_2=0.999\), \(\eta=10^{-3}\)) worked well enough that many practitioners never changed them.
Two important caveats emerged:
- Adam showed convergence pathologies in certain settings: the adaptive step size could increase at the wrong time, preventing convergence. AMSGrad fixed this by tracking the running maximum of \(\hat{v}_t\), ensuring effective learning rates never increase (Reddi et al., 2018). This was an important theoretical clarification, though in practice the next fix had more impact.
- Adding L2 regularization to the gradient (the standard way to implement “weight decay” in Adam) is not equivalent to true weight decay. The problem: when you add \(\lambda\theta\) to the gradient and then divide by \(\sqrt{\hat{v}_t}\), the regularization gets scaled differently for each parameter. Parameters with large gradients get less regularization than intended, and parameters with small gradients get more.
AdamW fixed the second issue by decoupling weight decay from the adaptive update (Loshchilov and Hutter, 2017). Instead of adding regularization to the gradient, it shrinks the weights directly after the Adam step:
\[ \theta_{t+1} = (1-\eta\lambda)\theta_t + \Delta\theta_t^{\text{adam}}. \]
This was a small implementation change, but it made weight decay behave as intended regardless of the adaptive scaling. AdamW became the standard for Transformers and most modern architectures.
Two other ingredients became part of the standard recipe around this time. Learning rate warmup ramps the learning rate up gradually in early training to let the moment estimates stabilize before taking large steps. The technique was used in earlier work including ResNet training, but became widely recognized through the Transformer paper (Vaswani et al., 2017) and large-batch studies (Goyal et al., 2017). Gradient clipping, introduced for exploding gradients in RNNs (Pascanu et al., 2013), caps the gradient norm to prevent occasional large updates from destabilizing a run. Together with AdamW, cosine learning rate decay, and careful weight decay exclusions, these form the baseline recipe that most frontier LLM training still uses.
2015 to 2023: beyond Adam on multiple fronts
After Adam became the default, several parallel lines of work tried to improve on it along different axes.
Curvature approximation
All the adaptive methods above (AdaGrad, RMSProp, Adam) are already doing a simple form of preconditioning: transforming the gradient before stepping. Adam divides each element of the smoothed gradient by \(\sqrt{\hat{v}_t}\), scaling each parameter independently. In linear algebra terms, this is the same as multiplying by a diagonal matrix: \(\Delta\theta = -\eta\, P\, \hat{m}_t\) where \(P\) has entries \(1/(\sqrt{\hat{v}_t} + \epsilon)\) on the diagonal and zeros elsewhere. Each parameter gets its own scale, but the optimizer ignores how parameters interact.
In reality, parameters within a layer are correlated: changing one weight affects what the optimal change for its neighbors should be. There is a spectrum of preconditioning richness:
- SGD: \(P = I\) (identity). No preconditioning at all.
- Adam: \(P\) is diagonal. Per-parameter scaling, but no cross-parameter information.
- K-FAC/Shampoo: \(P\) is a structured matrix. Captures correlations between parameters within a layer.
- Newton’s method: \(P = H^{-1}\) (full inverse Hessian). Captures everything, but for a layer with \(p\) parameters that means storing and inverting a \(p \times p\) matrix, which is impractical at scale.
K-FAC and Shampoo sit in the middle of this spectrum: richer than Adam, cheaper than Newton.
K-FAC approximated the Fisher information matrix using Kronecker factorization (Martens and Grosse, 2015). The key insight: for a layer with input activations \(a\) and output gradients \(g\), the Fisher block can be approximated as \(F \approx (aa^\top) \otimes (gg^\top)\), a Kronecker product of two much smaller matrices. For a layer with \(m\) inputs and \(n\) outputs, instead of storing and inverting a \(mn \times mn\) matrix, you store and invert one \(m \times m\) and one \(n \times n\) matrix separately. This captures correlations between parameters in the same layer at a fraction of full second-order cost.
Shampoo generalized this idea to per-block matrix preconditioners that don’t require the Fisher structure (Gupta et al., 2018). For a weight matrix \(W \in \mathbb{R}^{m \times n}\), Shampoo maintains left and right preconditioners \(L \in \mathbb{R}^{m \times m}\) and \(R \in \mathbb{R}^{n \times n}\), and updates with \(L^{-1/4} G\, R^{-1/4}\). Like K-FAC, this captures how parameters within a layer interact, but with a more general formulation.
Neither became a broad default. The implementation complexity and tuning overhead exceeded the gain in performance for most teams. But they proved that accounting for cross-parameter structure could outperform Adam’s independent scaling. Several years later, the 2024-2026 conditioning wave would revisit this same motivation with simpler methods.
Large-batch training
Larger batches give more accurate gradient estimates (less noise from mini-batch sampling), so in principle you can take larger steps. The standard fix is linear scaling: multiply the learning rate by \(k\) when you multiply the batch size by \(k\). But this breaks down in practice because different layers have different gradient magnitudes. A single global scaling factor either over-updates some layers or under-updates others.
LARS solved this with a layer-wise trust ratio (You et al., 2017). For each layer \(l\), the local learning rate is scaled by the ratio of weight norm to gradient norm:
\[ \eta_l = \eta \cdot \frac{\|w_l\|}{\|g_l\|}. \]
Layers with small weights relative to their gradients get smaller steps, preventing them from being blown up by an aggressive global rate. LAMB brought the same idea to Adam-style moments for large-batch language pretraining, enabling large-batch BERT training (You et al., 2019).
LARS and LAMB themselves did not become standard in frontier LLM or diffusion model training. The community settled on AdamW with careful scheduling instead. Still, the insight that different layers need different effective learning rates proved helpful for later development of optimizers, including the conditioning methods covered below.
Memory and systems
At Transformer scale, optimizer state is expensive. Adam stores two extra fp32 tensors per parameter (first and second moments), so optimizer state alone is 2x the model size, about 56 GB for a 7B-parameter model.
Adafactor addressed second-moment memory by factorizing it (Shazeer and Stern, 2018). Adam stores a full second-moment matrix \(v_t\) with the same shape as each parameter. For a weight matrix \(W \in \mathbb{R}^{m \times n}\), Adafactor instead stores row and column statistics \(r_t \in \mathbb{R}^m\) and \(c_t \in \mathbb{R}^n\), and reconstructs the second moment as their outer product: \(\hat{v}_t \approx r_t\, c_t^\top / \text{mean}(r_t)\). This reduces memory from \(O(mn)\) to \(O(m+n)\) per matrix parameter, which was critical for scaling T5-class models.
8-bit optimizer states took a different approach: keep Adam’s algorithm but quantize \(m_t\) and \(v_t\) to 8-bit integers with dynamic scaling, cutting state memory by roughly 75% with near-identical training behavior (Dettmers et al., 2021). This is now common in finetuning workflows.
Communication-aware variants like 1-bit Adam targeted distributed bandwidth by compressing the information exchanged between workers during training (Tang et al., 2021).
The best optimizer is not only mathematically elegant; it must fit systems constraints. For many teams, this is why AdamW kept winning despite stronger niche alternatives.
Other directions
SAM (Sharpness-Aware Minimization) penalizes sharp minima by optimizing for the worst-case loss in a small neighborhood around the current parameters, the idea being that flatter minima tend to generalize better (Foret et al., 2020):
\[ \min_\theta \max_{\|\epsilon\| \le \rho} \mathcal{L}(\theta + \epsilon). \]
In practice, the inner max is approximated with a single gradient ascent step: \(\hat\epsilon = \rho\, g / \|g\|\), then the model is updated using the gradient at \(\theta + \hat\epsilon\).
Lion (Chen et al., 2023) took a different approach entirely: discover the update rule through automated program search rather than manual design. The result uses only the sign of a momentum-like term as the update. It validated optimizer design as a search problem, though it did not displace AdamW broadly. Many other variants from this period (Lookahead, RAdam, AdaBelief, AdaBound) explored warmup and update coupling tweaks but saw limited adoption.
2024 to 2025: geometry returns
Muon-style methods reframed the problem. Adam scales each parameter independently; it doesn’t account for how parameters within a layer interact. In practice, a few dominant directions in the weight matrix can hog the update while others are neglected. Muon reshapes the gradient to spread the update more evenly across directions (Muon implementation, modular-duality framing).
The key operation is polar decomposition. For a gradient matrix \(G\), any matrix can be decomposed as \(G = U S\) where \(U\) is orthogonal and \(S\) is symmetric positive semi-definite. Muon uses \(U\), the orthogonal factor, as the update direction:
\[ \Delta\theta = -\eta\, \text{polar}(G), \quad \text{where } \text{polar}(G) = G\,(G^\top G)^{-1/2}. \]
This ensures the update has equal magnitude across all directions, preventing any single direction from dominating. In practice, the matrix inverse square root is approximated cheaply using a few iterations of Newton-Schulz, avoiding the cost of a full SVD.
Early results showed Muon scaling competitively to 1B+ parameters (Jordan et al., 2025), with a simpler implementation surface than K-FAC or Shampoo.
By end-2025, this looked promising but not universal. AdamW still dominated documented frontier recipes. So the open question entering 2026 became replication at larger scales, not just first-paper wins.
Late-2025 to early-2026: conditioning wave
A broader conditioning-focused wave followed. All of these methods share a common structure: transform the gradient \(G\) through some structured preconditioner \(P\) before updating:
\[ \Delta\theta = -\eta\, P(G). \]
In base Muon, \(P(G) = \text{polar}(G)\). The new methods modify what goes into \(P\), what \(P\) does, or what happens after:
NorMuon adds per-neuron adaptive scaling after orthogonalization. It tracks a row-wise running second moment of the orthogonalized update \(O_t = \text{polar}(M_t)\), then normalizes each row by its own RMS (2025) [1B+, open-source]:
\[ v_t = \beta_2\, v_{t-1} + (1-\beta_2)\,\text{mean}_{\text{cols}}(O_t \odot O_t), \qquad \hat{O}_t = O_t \,/\, (\sqrt{v_t} + \epsilon). \]
This is essentially Adam-style adaptive scaling, but applied per neuron to the post-orthogonalization update rather than per element to the raw gradient.
MARS-M modifies what goes into the Muon pipeline. It replaces the raw stochastic gradient with a variance-reduced estimator before momentum and orthogonalization (2025) [theory, small-scale, open-source]:
\[ C_t = \nabla f(\theta_t, \xi_t) + \gamma_t \tfrac{\beta}{1-\beta}\bigl[\nabla f(\theta_t, \xi_t) - \nabla f(\theta_{t-1}, \xi_t)\bigr]. \]
The correction term uses the same mini-batch \(\xi_t\) at both the current and previous iterate, reducing the variance of the momentum estimate at the cost of one extra gradient evaluation per step.
Hyperparameter transfer for matrix preconditioners showed that conditioning gains persist when transferring optimizer configs from small to large runs, making these methods more practical to tune (2025) [1B+, protocol].
TEON changes the structure of the orthogonalization. Where Muon orthogonalizes each layer’s gradient independently, TEON stacks \(K\) same-shape layer gradients into a tensor, unfolds along a chosen mode, and orthogonalizes the unfolded matrix (2026) [theory, 1B-range]:
\[ \mathcal{O}_i(\mathcal{G}) = \mathcal{M}_i^{-1}\!\bigl(\text{polar}\bigl(\mathcal{M}_i(\mathcal{G})\bigr)\bigr), \]
where \(\mathcal{M}_i\) is the mode-\(i\) matricization (unfolding) of the stacked tensor \(\mathcal{G} \in \mathbb{R}^{m \times n \times K}\). This captures cross-layer correlations that per-layer Muon misses.
ARO changes the coordinate system in which the optimizer operates. It selects an adaptive rotation \(R_t\) that maximizes instantaneous loss decrease, rather than using the gradient’s own eigenstructure (2026) [1B+, protocol]:
\[ \Delta W_t = -\eta\, R_t\, f_t(R_t^\top M_t), \qquad R_t = \text{QR}\!\bigl(M_t\, f_t(R_{t-1}^\top M_t)^\top\bigr). \]
The rotation at step \(t\) depends on the previous step’s rotated projection, creating a feedback loop between the rotation and the base optimizer. Base Muon is a special case where \(R_t\) is fixed to the eigenvectors of \(M_t M_t^\top\).
The shift: conditioning is becoming a primary design axis, not a side detail. Evidence labels above ([1B+], [theory], etc.) indicate maturity; most of these methods have open-source implementations but limited independent replication so far.
Community reports (Muon comparisons, distributed Muon validation) are useful early signals, though controlled evaluations remain more reliable before committing to large-scale runs.
What won in practice by early 2026
Defaults remain fairly stable:
- Frontier LLMs and VLMs (vision-language models): AdamW + warmup + decay + gradient clipping + selective decay exclusions.
- ViTs (Vision Transformers): AdamW.
- CNNs: SGD + momentum remains strong.
- Diffusion and flow-matching models: Adam/AdamW, often with EMA (exponential moving average of weights).
- LARS/LAMB: useful in specific extreme-batch throughput regimes.
Recipe chooser (2025 to early-2026)
| Setting | First choice | When to deviate |
|---|---|---|
| LLM/VLM pretraining | AdamW + warmup/decay + clipping | Try Muon/conditioning if stability or scaling efficiency is bottleneck |
| Vision CNN | SGD + momentum + strong LR schedule | Use AdamW for transformer-heavy stacks or faster early convergence |
| ViT training | AdamW | Trial SAM or conditioning methods when plateaus appear |
| Diffusion/flow matching | AdamW (+ EMA) | Try Adafactor/low-precision states when memory dominates |
| Extreme large-batch throughput | LARS/LAMB | Stay with AdamW if batch size is moderate and tuning budget is limited |
Starting hyperparameters
These are typical starting points, not universal optima. Always tune on your workload.
| Optimizer | Learning rate | beta1, beta2 | Weight decay | Notes |
|---|---|---|---|---|
| AdamW (LLM) | 1e-4 to 6e-4 | 0.9, 0.95 | 0.01 to 0.1 | Warmup 1-5% of steps, cosine decay |
| AdamW (ViT) | 1e-4 to 3e-4 | 0.9, 0.999 | 0.01 to 0.3 | Higher decay common with strong augmentation |
| SGD + momentum (CNN) | 0.01 to 0.1 | momentum 0.9 | 1e-4 to 5e-4 | Step or cosine LR schedule |
| Muon | 0.01 to 0.05 | 0.9, n/a | 0.0 to 0.01 | Orthogonalization replaces some of weight decay’s role |
Fair comparison protocol
- Same model and tokenizer.
- Same token/image budget and data order.
- Matched tuning budget across optimizers.
- Report time-to-target, compute-to-target, and seed stability.
Closing
From heavy-ball momentum to conditioning-heavy methods, optimizer history is mostly a story of recurring constraints in new forms: curvature, noise, scale, and hardware budgets. Innovation keeps happening because three forces (theory, empirical pressure, and systems constraints) keep interacting. Methods that survive usually satisfy all three.
By early 2026, AdamW is still the center of gravity. The next durable shift is likely to come from better directional control and structured conditioning, not just better scalar learning-rate heuristics. What to watch for in the rest of 2026:
- Whether conditioning methods (Muon-family, ARO, TEON) show consistent gains under independent replication at 10B+ scale.
- Whether hyperparameter transfer protocols make these methods usable without per-run tuning.
- Whether systems-level integration (fused kernels, native framework support) lowers the adoption barrier enough to challenge AdamW as the default baseline.
The optimizer that wins next will not just be mathematically better; it will be easier to deploy correctly at scale.